We’re excited to share with you outcomes from two Zooniverse initiatives, ‘Etch A Cell – Fats Checker’ and ‘Etch A Cell – Fats Checker Spherical 2’. Over the course of those two initiatives, greater than 2000 Zooniverse volunteers contributed over 75 thousand annotations!
One of many core goals of those two initiatives was to allow the design and implementation of machine studying approaches that would automate the annotation of fats droplets in novel knowledge units, to offer a place to begin for different analysis groups making an attempt to carry out comparable duties.
With this in thoughts, we’ve developed a number of machine studying algorithms that may be utilized to each 2D and 3D fats droplet knowledge. We describe these fashions within the weblog publish under.
Machine studying fashions for the segmentation of fats droplets in 2D knowledge
Patch Generative Adversarial Community (PatchGAN)
Generative Adversarial Networks (GANs) had been launched in 2018 for the aim of lifelike studying of image-level options and have been used for varied pc imaginative and prescient associated functions. We applied a pixel-to-pixel translator mannequin known as PatchGAN, which learns to transform (or “translate”) an enter picture to a different picture kind. For instance, such a framework can be taught to transform a gray-scale picture to a coloured model.
The “Patch” in PatchGAN signifies its functionality to be taught picture options in numerous sub-portions of a picture (reasonably than simply throughout a whole picture as an entire). Within the context of the Etch A Cell – Fats Checker undertaking knowledge, predicting the annotation areas of fats droplets is analogous to PatchGAN’s image-to-image translation activity.
We skilled the PatchGAN mannequin framework on the ~50K annotations generated by volunteers in Etch A Cell – Fats Checker. Beneath we present two instance photos from the Etch A Cell: Fats Checker (left column) together with aggregated annotations offered by the volunteers (center panel), and their corresponding 2D machine studying mannequin (PatchGAN) predicted annotations.

We discovered that the PatchGAN usually carried out nicely in studying the topic picture to fat-droplet annotation predictions. Nevertheless, we observed that the mannequin highlighted some areas probably missed by the volunteers, in addition to cases the place it has underestimated some areas that the volunteers have annotated (often intermediate to small sized droplets).
We made have made this work, our generalized PatchGAN framework, out there by way of an open-source repository at https://github.com/ramanakumars/patchGAN and https://pypi.org/undertaking/patchGAN/. This can enable anybody to simply prepare the mannequin on a set of photos and corresponding masks, or to make use of the pre-trained mannequin to deduce fats droplet annotations on photos they’ve at hand.
UNet, UNet3+, and nnUNet
Along with the above-mentioned PatchGAN community, we’ve additionally skilled three further frameworks for the duty of fats droplet identification – UNet, UNet3+, and nnUNet.
UNet is a well-liked deep-learning methodology used for semantic segmentation inside photos (e.g., figuring out automobiles/visitors in a picture) and has been proven to seize intricate picture particulars and exact object delineation. Its structure is U-shaped with two elements – an encoder that learns to cut back the enter picture down a compressed “fingerprint” and a decoder which learns to foretell the goal picture (e.g., fats droplets within the picture) based mostly on that compressed fingerprint. Effective-grained picture data is shared between the encoder and decoder elements utilizing the so-called “skip connections”. UNet3+ is an upgraded framework constructed upon the foundational UNet that has been proven to seize each native and world options inside medical photos.
nnUNet is an user-friendly, environment friendly, and state-of-the-art deep studying platform to coach and fine-tune fashions for various medical imaging duties. It employs a UNet-based structure and comes with picture pre-processing and post-processing strategies.
We skilled these three networks on the info from the Fats Checker 1 undertaking. Beneath, we present three instance topic photos together with their corresponding volunteer annotations and completely different mannequin predictions. Between the three fashions, nnUNet demonstrated superior efficiency.

Machine studying fashions for the segmentation of fats droplets in 3D knowledge
Temporal Cubic PatchGAN (TCuP-GAN
Motivated by the 3D volumetric nature of the Etch A Cell – Fats Checker undertaking knowledge, we additionally developed a brand new 3D deep studying methodology that learns to foretell the direct 3D areas comparable to the fats droplets. To develop this, we constructed on high of our efforts of our PatchGAN framework and merged it with one other pc imaginative and prescient idea known as “LongShort-Time period Reminiscence Networks (LSTMs)”. Briefly, lately, LSTMs have seen large success in studying sequential knowledge (e.g., phrases and their relationship inside a sentence) and so they have been used to be taught relationships amongst sequences of photos (e.g., motion of a canine in a video).
We’ve efficiently applied and skilled our new TCuP-GAN mannequin on the Etch A Cell – Fats Checker knowledge. Beneath is an instance picture dice – containing a group of 2D picture slices that you simply considered and annotated – together with the fats droplet annotation prediction of our 3D mannequin. For visible steerage, we present the center panel the place we diminished the transparency of the picture dice proven within the left panel, highlighting the fats droplet buildings that lie inside.
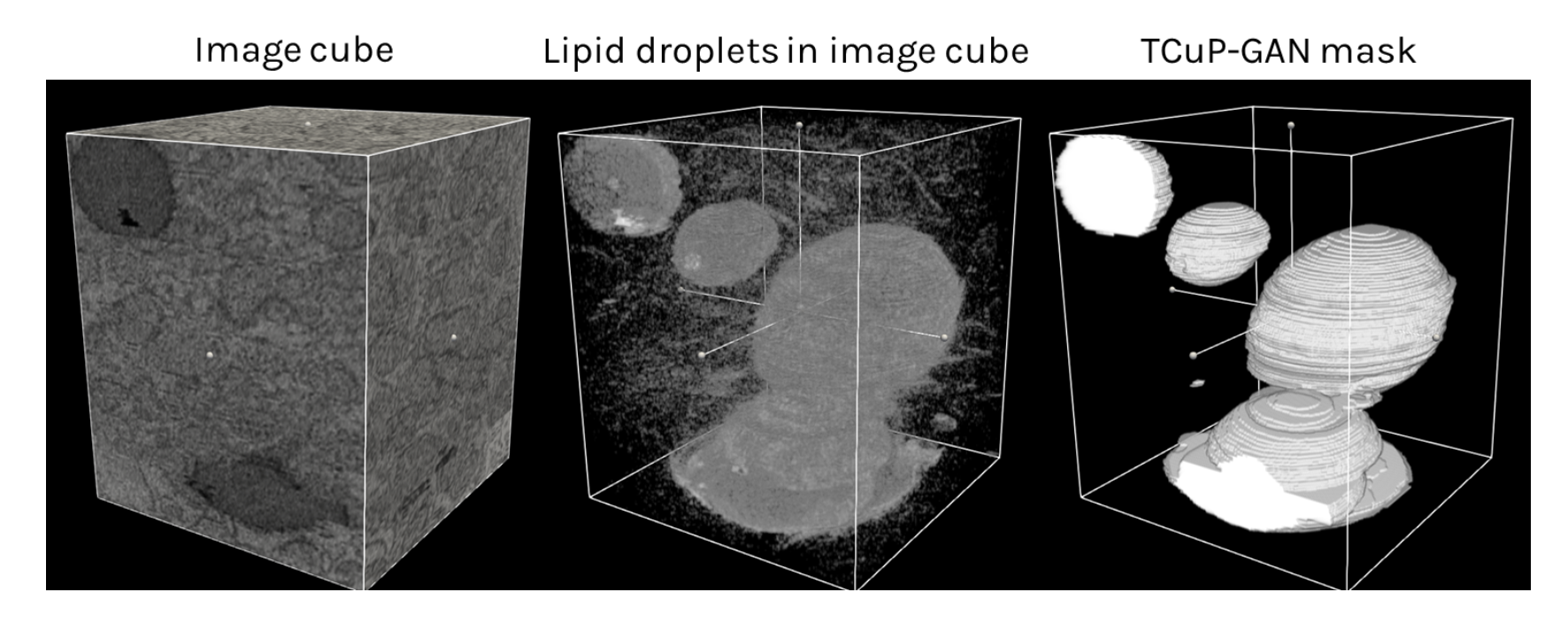
We discovered that our TCuP-GAN mannequin efficiently predicts the 3D fats droplet buildings. In doing so, our mannequin additionally learns lifelike (and informative) signatures of lipid droplets inside the picture. Leveraging this, we’re capable of ask the mannequin which 2D picture slices comprise probably the most confusion between lipid droplets and surrounding areas of the cells relating to annotating the fats droplets. Beneath, we present two instance slices the place the mannequin was assured in regards to the prediction (i.e., much less confusion; high panel) and the place the mannequin was considerably confused (crimson areas in fourth column of the underside panel). As such, we demonstrated that our mannequin may help discover these photos within the knowledge set that preferentially require data from the volunteers. This will function a possible effectivity step for future analysis groups to prioritize sure photos that require consideration from the volunteers.

Integrating Machine Studying Methods with Citizen Science
A number of hundreds of annotations collected from the Etch A Cell – Fats Checker undertaking(s) and their use to coach varied machine studying frameworks have opened up prospects that may improve the effectivity and annotation gathering and assist speed up the scientific outcomes for future initiatives.
Whereas the fashions we described right here all carried out fairly nicely in studying to foretell the fats droplets, there have been a considerable variety of topics the place they had been inaccurate or confused. Rising “human-in-the-loop” methods have gotten more and more helpful in these circumstances – the place citizen scientists may help with offering vital data on these topics that require probably the most consideration. Moreover, an imperfect machine studying mannequin can present an preliminary guess which the residents can use as a place to begin and supply edits, which is able to tremendously tremendously cut back the quantity of effort wanted by particular person citizen scientists.
For our subsequent steps, utilizing the info from the Etch A Cell – Fats Checker initiatives, we’re working in direction of constructing new infrastructure instruments that may allow future initiatives to leverage each citizen science and machine studying in direction of fixing vital analysis issues.
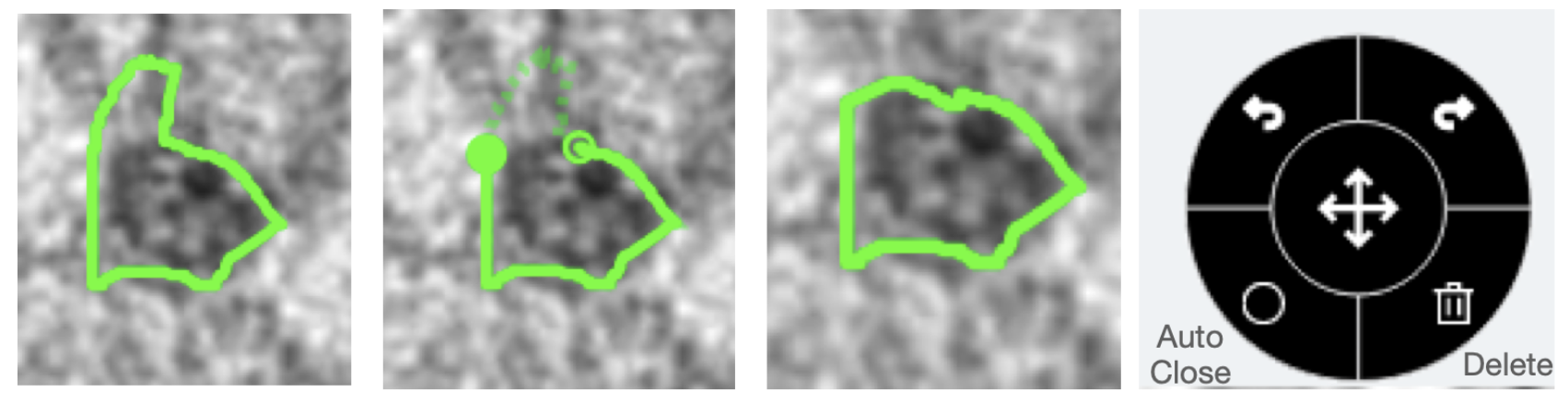
First, we’ve made upgrades to the present freehand line drawing instrument on Zooniverse. Particularly, customers will now be capable to edit a drawn form, undo or redo throughout any stage of their drawing course of, mechanically shut open shapes, and delete any drawings. Beneath is a visualization of an instance drawing the place the center panel illustrates the enhancing state (indicated by the open dashed line) and re-drawn/edited form. The instrument field with undo, redo, auto-close, and delete capabilities can be proven.
A brand new “right a machine” framework
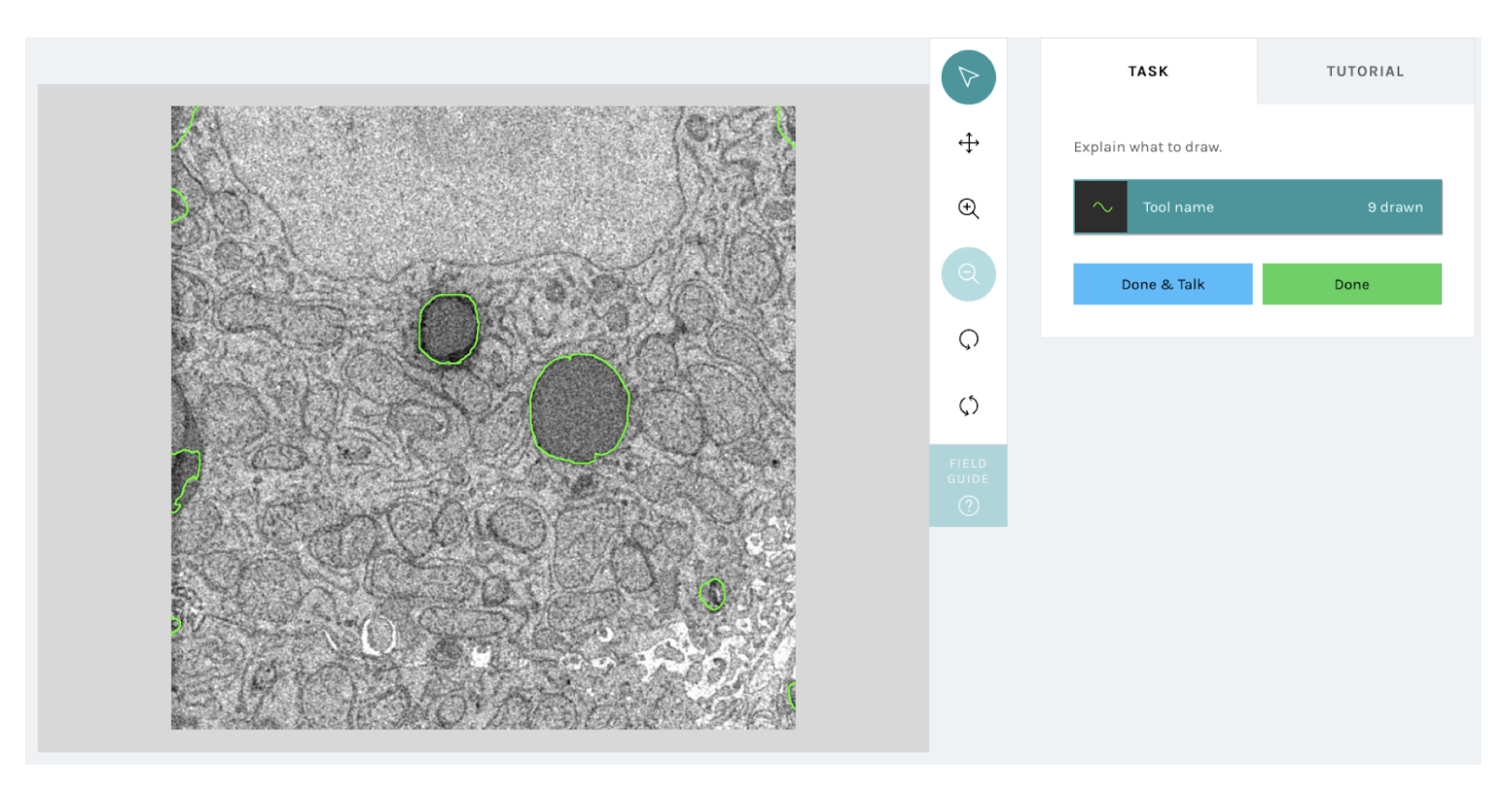
We’ve constructed a brand new infrastructure that may allow researchers to add machine studying (or every other automated methodology) based mostly outlines in a suitable format to the freehand line instrument such that every topic when considered by a volunteer on a Zooniverse can be proven the pre-loaded machine outlines, which they’ll edit utilizing the above newly-added performance. As soon as volunteers present their corrected/edited annotations, their responses can be recorded and utilized by the analysis groups for his or her downstream analyses. The determine under reveals an instance visualization of what a volunteer would see with the brand new right a machine workflow. Observe, that the inexperienced outlines proven on high of the topic picture are straight loaded from a machine mannequin prediction and volunteers will be capable to work together with them.
From Fats Droplets to Floating Forests
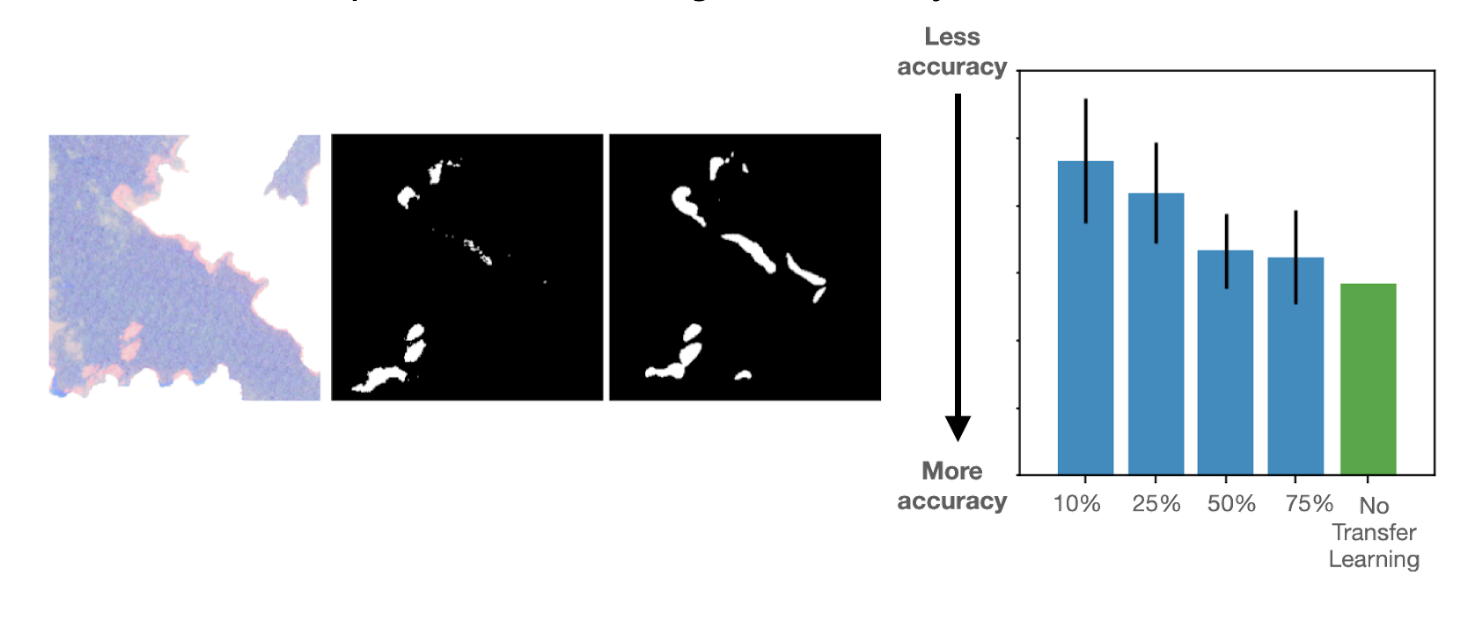
Lastly, the volunteer annotations submitted to those two initiatives will have an effect far past the fats droplets identification in biomedical imaging. Impressed by the flexibleness of the PatchGAN mannequin, we additionally carried out a “Switch Studying” experiment, the place we examined if a mannequin skilled to determine fats droplets can be utilized for a unique activity of figuring out kelp beds in satellite tv for pc imaging. For this, we used the info from one other Zooniverse undertaking known as Floating Forests.
By this work, we discovered that our PatchGAN framework readily works to foretell the kelp areas. Extra apparently, we discovered that when our pre-trained mannequin to detect fats droplets inside Fats Checker undertaking knowledge was used as a place to begin to foretell the kelp areas, the resultant mannequin achieved excellent accuracies with solely a small variety of coaching photos (~10-25% of the general knowledge set dimension). Beneath is an instance topic together with the volunteer annotated kelp areas and corresponding PatchGAN prediction. The bar chart illustrates how the Etch A Cell – Fats Checker based mostly annotations may help cut back the quantity of annotations required to attain a great accuracy.
In abstract: THANK YOU!
In abstract, with the assistance of your participation within the Etch A Cell – Fats Checker and Etch A Cell – Fats Checker Spherical 2 initiatives, we’ve made nice strides in processing the info and coaching varied profitable machine studying frameworks. We’ve additionally made a variety of progress in updating the annotation instruments and constructing new infrastructure in direction of making one of the best partnership between people and machines for science. We’re trying ahead to launching new initiatives that use this new infrastructure we’ve constructed!
This undertaking is a part of the Etch A Cell organisation

‘Etch A Cell – Fats Checker’ and ‘Etch A Cell – Fats Checker spherical 2’ are a part of The Etchiverse: a group of a number of initiatives to discover completely different elements of cell biology. If you happen to’d wish to become involved in a few of our different initiatives and be taught extra about The Etchiverse, you could find the opposite Etch A Cell initiatives on our organisation web page right here.
Thanks for contributing to Etch A Cell! – Fats Checker!
